Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
安装
安装过程请根据自己使用的平台自行 Google,这里是官方的安装指南
创建项目
本项目用于爬取 豆瓣电影Top250 数据,开发工具为 PyCharm
项目地址:douban
Scrapy 需要用命令行创建一个项目:
1
| $ scrapy startproject douban
|
项目结构:
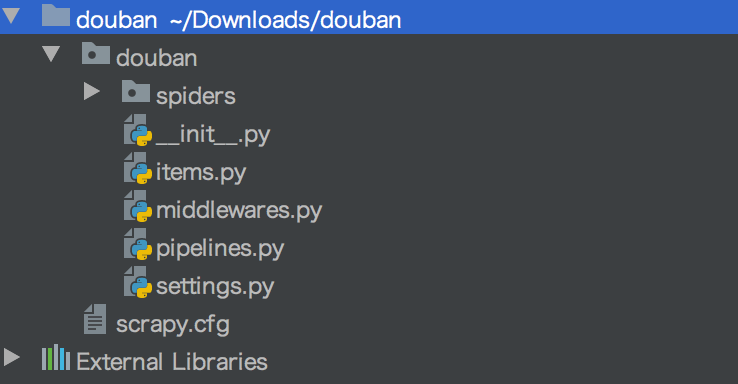
scrapy.cfg:项目配置文件douban/setting.py:爬虫的设置文件douban/spiders/:爬虫放置文件位置
修改配置文件
需要修改 setting.py 中请求头信息
chrome 访问豆瓣电影Top250 ,然后打开开发者工具并选择 Network 标签,最后刷新界面:
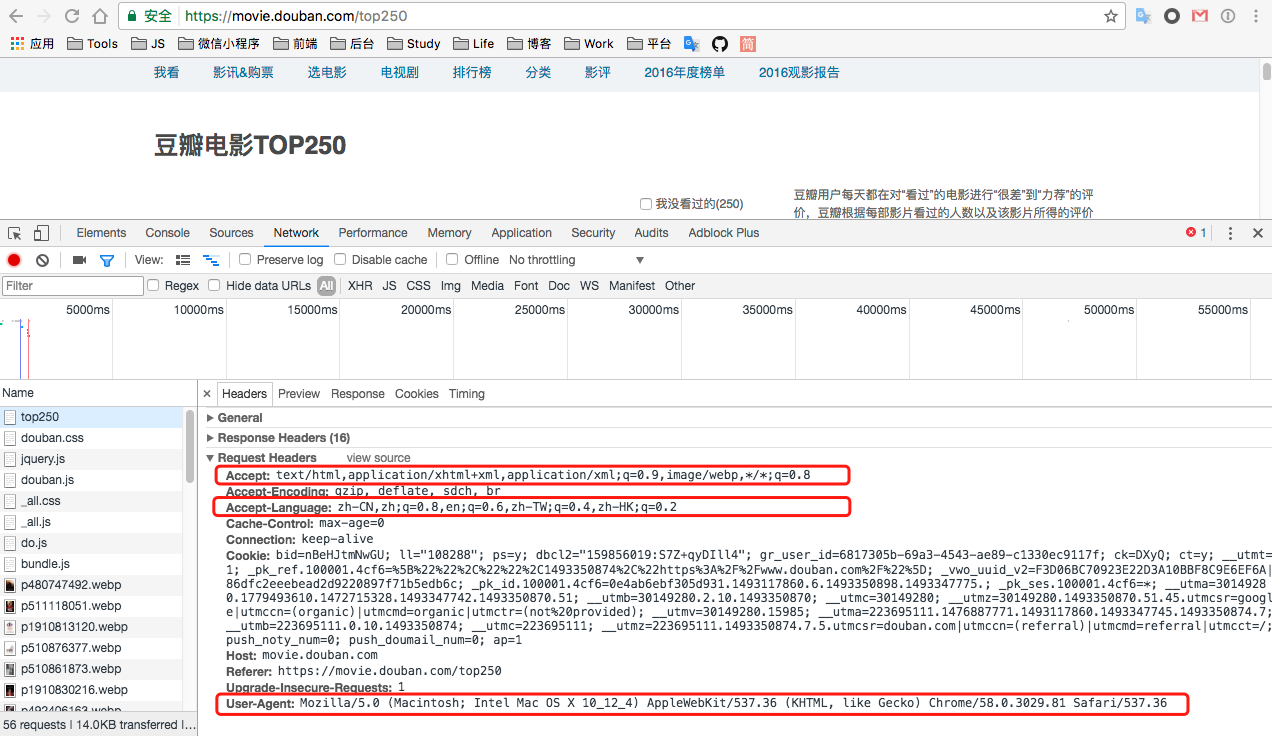
根据获取到的数据修改 setting.py 文件:
1
2
3
4
5
6
7
8
|
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/event-stream',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4,zh-HK;q=0.2',
}
|
定义数据对象
需要为爬取到的数据提供一个对象,和 Java 中的对象类似,继承于 scrapy.Item 类,定义类型为 scrapy.Field 的属性字段:
1
2
3
4
5
6
7
8
| import scrapy
class Item(scrapy.Item):
title = scrapy.Field()
pic = scrapy.Field()
link = scrapy.Field()
score = scrapy.Field()
commentsNum = scrapy.Field()
|
创建爬虫
scrapy 提供了命令行工具,可以很方便的根据框架中的模板创建一个爬虫
1
2
3
4
5
6
|
$ scrapy genspider -l
$ scrapy genspider -d basic
$ scrapy genspider -t basic doubanMovie douban.com
|
生成的 doubanMovie.py 文件:
1
2
3
4
5
6
7
8
9
10
|
import scrapy
class DoubanmovieSpider(scrapy.Spider):
name = "doubanMovie"
allowed_domains = ["douban.com"]
start_urls = ['http://douban.com/']
def parse(self, response):
pass
|
name:spider 名字,必须是唯一的allowed_domains:允许爬取的域名start_urls:开始爬取的 URLparse():spider 的一个方法,调用时,会把 start_urls 中 URL 下载生成的 Response 对象作为唯一参数传递给该方法。该方法负责解析返回的数据,提取数据和生成需要进一步处理的 Request 对象
修改 start_urls 为我们要爬取的 豆瓣电影Top250 ,并用 XPath 解析 Response 对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import scrapy
from douban.movie import Movie
import re
class DoubanMovieSpider(scrapy.Spider):
name = "doubanMovie"
allowed_domains = ["douban.com"]
start_urls = [
'https://movie.douban.com/top250',
]
def parse(self, response):
item = Movie()
for sel in response.xpath('//div[@class="item"]'):
item['title'] = sel.xpath('div/a/img/@alt').extract_first()
item['pic'] = sel.xpath('div/a/img/@src').extract_first()
item['link'] = sel.xpath('div/a/@href').extract_first()
item['info'] = sel.xpath('div[2]/div[2]/p[2]/span/text()').extract_first()
item['score'] = sel.xpath('div[2]/div[2]/div/span[2]/text()').extract_first()
item['commentsNum'] = sel.xpath('div[2]/div[2]/div/span[4]/text()').re(r'[0-9]+')[0]
yield item
|
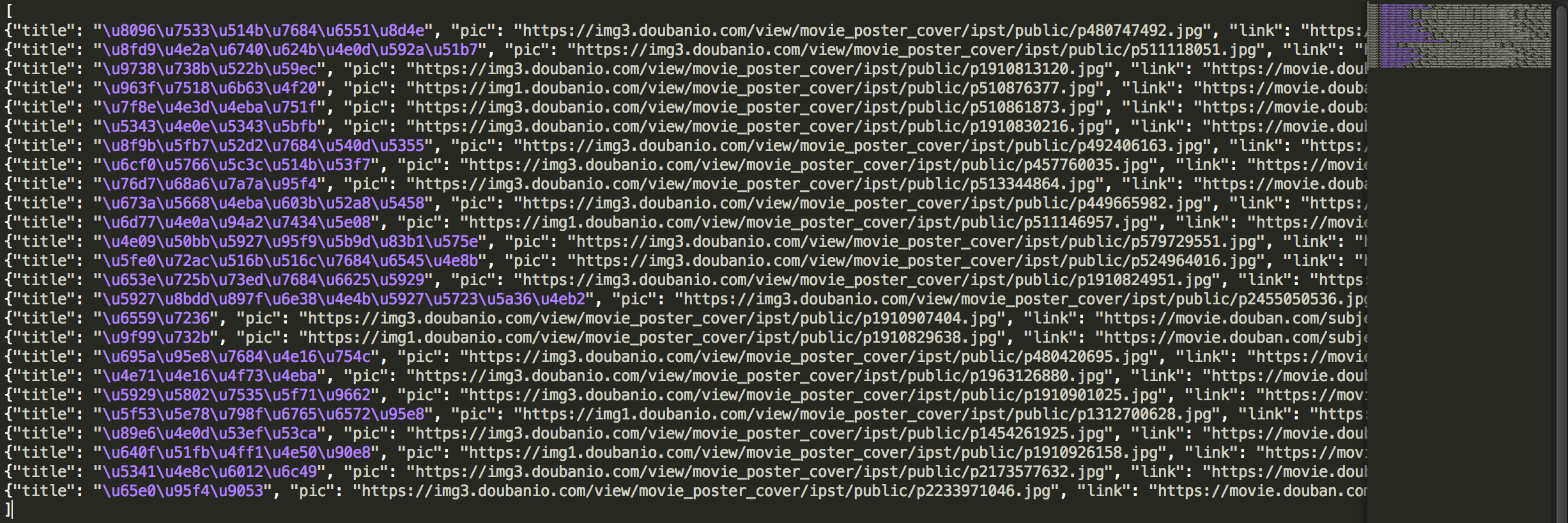
到此就可以爬取 豆瓣电影Top250 中第一页的内容了,在命令行中进入项目根目录输入运行命令开始爬取内容并输出到文件中:
1
| $ scrapy crawl doubanMovie -o ~/Downloads/doubanMovie.json
|
doubanMovie.json 文件内容:
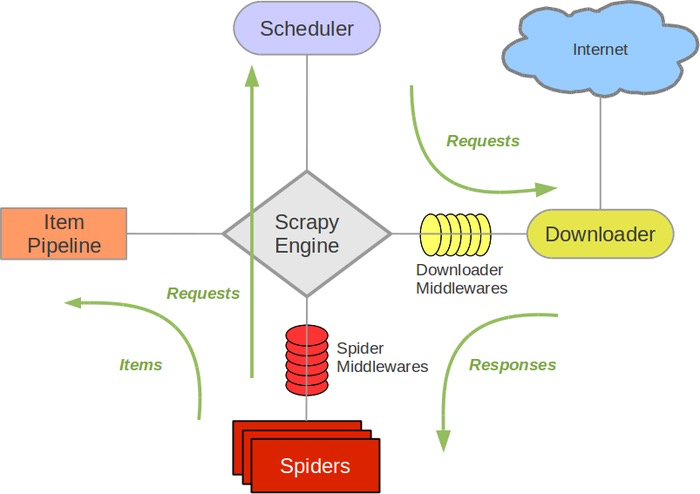
数据流
评论